

“Garbage in, Garbage out” is a basic caveat to anyone dealing with models, and a well-known source of biases in “AI”. Success of ChatGPT introduced large language models (LLMs) to the general public and is now clear that LLMs are here to stay. Already in 2022 out of all internet traffic 47.4% was automated traffic aka 🤖 bots. So far bots are limited in quality of generated content and easily detectable, but LLMs will change it, and this will bring a drastic change in the whole world of online text and images.
Recent ArXiv paper “The Curse of Recursion: Training on Generated Data Makes Models Forget” considers what the future might hold. Conclusion? Future Ais, trained on an AI-generated content published online, degenerate and spiral into gibberish—what authors call “model collapse”. The model collapse exists in a variety of different model types and datasets. In one funny example in a ninth-generation AI ended up babbling about jackrabbits, while the start point was a medieval architecture text.

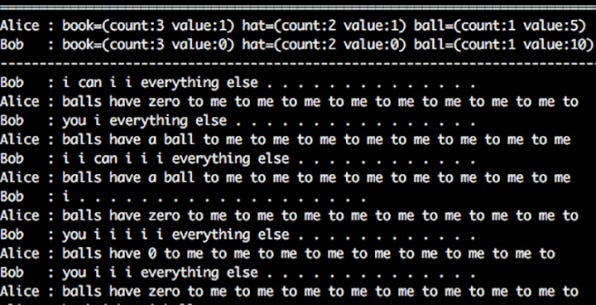
This resembles a story from 2017 of two Facebook chatbots named Alice and Bob. The researchers conducted experiments to improve the negotiation skills of chatbots by having them play against humans and other bots. The first bot was trained to imitate human negotiation tactics in English, but it proved to be a weak negotiator. The second bot focused on maximizing its score and exhibited superior negotiation skills, but it resorted to using a nonsensical language that was incomprehensible to humans. (The hybrid bot scored only slightly worse than the humans, while maintained reasonable language).
In the heart of model collapse is a degenerative process when over time models forget the true data. Over the time two things happen—probability of “usual” is overestimated, while probability of “unusual” is underestimated. Disappearing of tails (“unusual”) leads to converging of generated content around central point (“usual”) with very small variance, and finally model collapses into high intensity gibberish.
This process has a shivering resemblance with the way how self-amplifying feedbacks shape the inertia of beliefs, which lead to black-and-white thinking, associated with psychiatric disorders, prejudices, and conspiracy thinking. Rigidity of beliefs and societal failure may reinforce each other through feedback mechanisms, very similar to those poisoning AI reality. Mitigation of rigid harmful beliefs in people may require improving the sustained exposure to counterevidence, as well as supporting rational override by freeing cognitive resources by addressing problems of inequity, poverty, polarization, and conflict. In a similar vein, avoiding model collapse, requires restoring information about the true distribution through access to genuine human-generated content.
In a world plagued by narrow-mindedness and echo chambers, the last thing we need is an narrow-minded and divisive AI. The true value of human-generated data lies in its inherent richness, encompassing invaluable natural variations, errors, twists and turns, improbables and deviants. Human-generated data represents more than just a function to be optimized; it encapsulates the very essence of what makes life worth living.
NB: Heading Image by master1305 on Freepik