
Recent developments in AI resulted in impressive tools, like a model for image generation. For instance, DALL-E 2 grabbed many headlines, as it can create realistic images and art from a description in natural language. While the generated images are impressive, basic questions remains unanswered—how does the model grasp relations between objects and agents? Relations are fundamental for human reasoning and cognition. Hence, machine models that aim to human-level perception and reasoning should have the ability to recognize relations and adequately reflect them in generative models.
Recent paper “Testing Relational Understanding in Text-Guided Image Generation” puts this assumption in test. The researchers generated galleries of DALL-E 2 images, using sentences with basic relationships—e.g. “a child touching a bowl” or “a cup on a spoon”. Then they showed images and prompt sentences to 169 participants and asked them to select images that match prompt. Only some 20% of images were perceived to be relevant to their associated prompts, across the 75 distinct prompts. Agentic prompts (somebody is doing something) generated slightly higher agreement, 28%. Physical prompts (X position in relation to Y) showed even lower agreement, 16%. The chart shows the proportion of participants reporting agreement between image and prompt, by the specific relation being tested. Only 3 relations entail agreement significantly above 25% (“touching”, “helping”, and “kicking”), and no relations entail agreement above 50%.
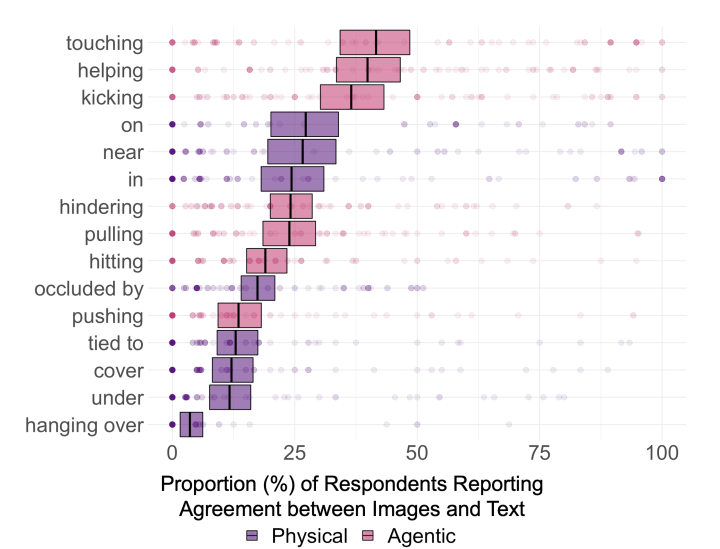
The results suggest that the model do not yet have a grasp of even basic relations involving simple objects and agents. Second, model has a special difficulty with imagination, i.e. ability to combine elements previously not combined in training datasets. For instance, the prompt “a child touching a bowl” generate images with high agreement (87%), while “a monkey touching an iguana” show worse results (11%). “A spoon in a cup” is easily generated, but not “a cup on a spoon”, reflecting effects of training data on model success.